はじめに
今回この記事を書こうと思ったきっかけですが、業務でカスタム区切り記号のテキストファイルを使用したときに意図しない挙動をしてハマったのが理由です。
具体的にはAthenaのテーブル作成にてGUIからカスタム区切り記号のテキストファイルを選択し、指定した場合、入力値と作成後のテーブル情報が異なるという現象が起きました。
これらの事象を調べたのでまとめようと思います。
動作確認環境
- 確認日: 2019/06/10
- リージョン: シンガポール
- サービス: Athena
- 言語設定: 日本語
ハマった箇所
手順
Athenaコンソールからテーブル作成、from S3 bukect data を選択
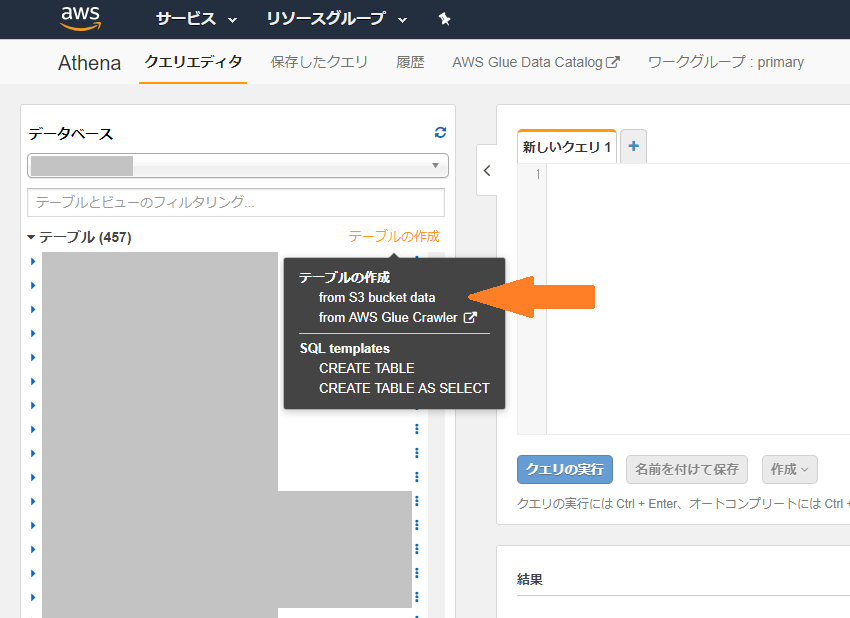
データ形式ステップにてカスタム区切り記号のテキストファイルを選択しテーブルを作成します
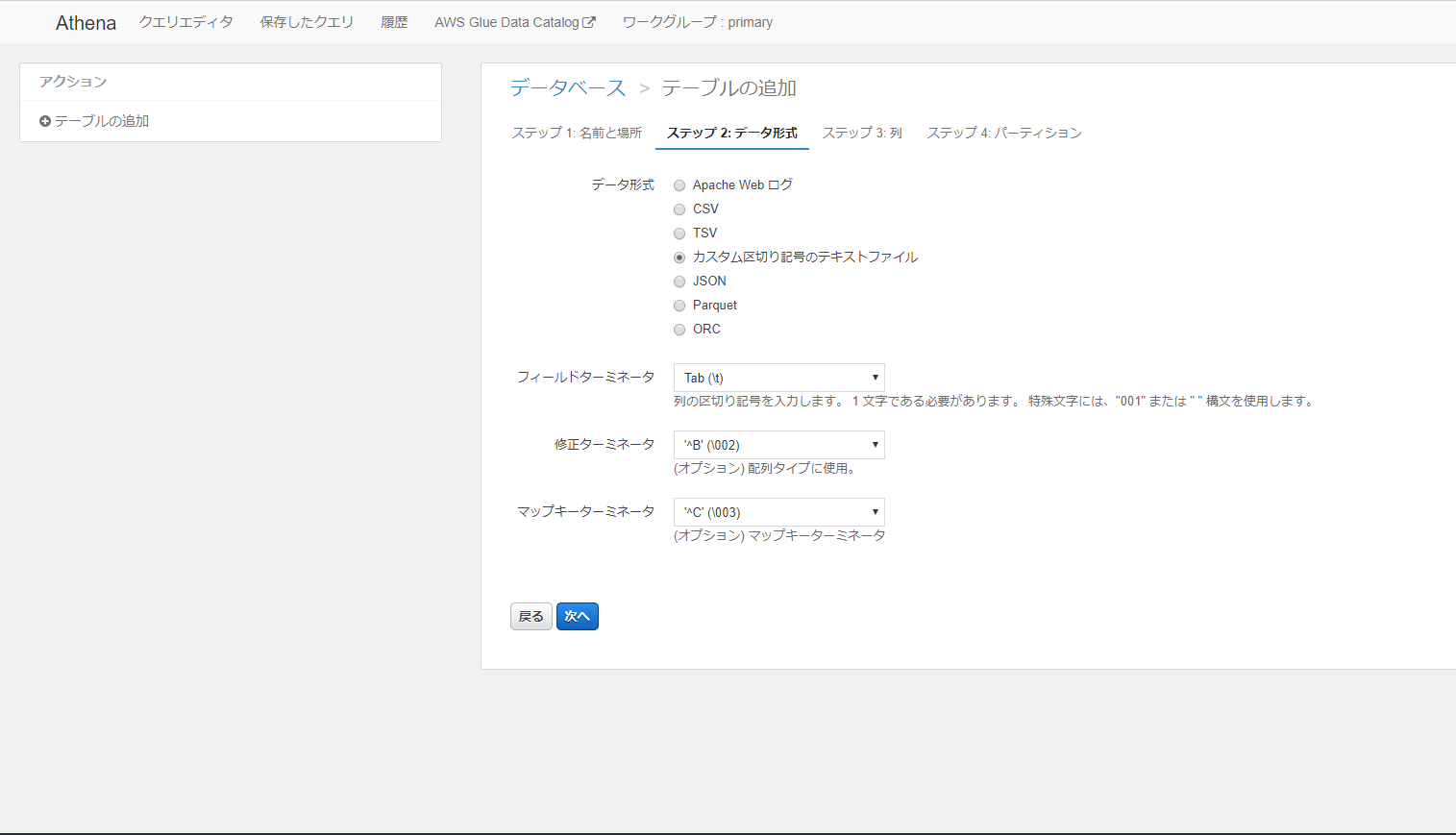
その後、CREATE TABLE文が実行されるがここで意図しない挙動を示しました。
カスタム区切り記号のテキストファイルの意図しない挙動
カスタム区切り記号のテキストファイル(Text File with Custom Delimiters)でセレクトボックスから選択しテーブルを作成すると下記の画像のようなクエリが実行されます。
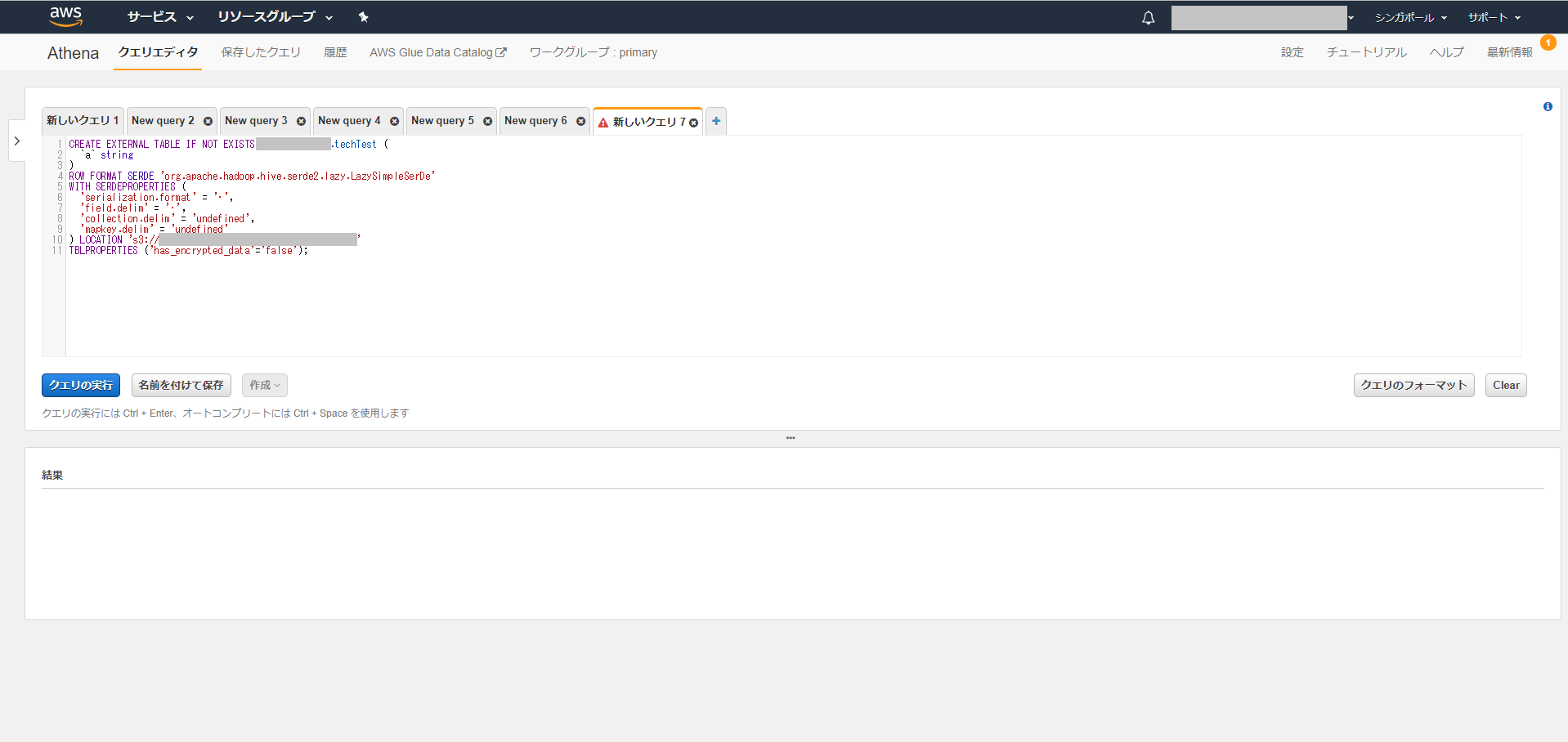
実際には下記の表のとおりに入力したにも関わらずクエリは入力値と異なる結果となってしまいました。
| フィールドターミネータ(Field terminator) | 修正ターミネータ(Collection terminator) | マップキーターミネータ(Map key terminator) | シリアライゼーション(serialization.format) | |
|---|---|---|---|---|
| 入力値 | ‘^A’ | ‘^B’ | ‘^C’ | |
| SQLのパラメータ | ‘^A’ | undifined | undifined | ‘^A’ |
また^Aなどの文字はエディタには「・」と表記される(見た目だけ)ので適当なクエリエディタにコピーし中身を確かめないとわかりません。
他にも入力値と実際の値を表にしてみました。
| フィールドターミネータ field.delim(入力値/実際の値) | 修正ターミネータ collection.delim(入力値/実際の値) | マップキーターミネータ mapkey.delim (入力値/実際の値) | シリアライゼーション serialization.delim |
|---|---|---|---|
| ^A/ ^A | ^B / undifined | ^C / undifined | ^A |
| ^B/^B | ^C/^C | ^A/^A | ^B |
| ^A/^A | ^C/^C | ^B/^B | ^A |
| ^B/^B | ^A/^A | ^C/undifined | ^B |
| ^C/^C | ^A/^A | ^B/^B | ^C |
| ^C/^C | ^B/undifined | ^A/^A | ^C |
| ^C/^C | ^A/^A | ^B/^B | ^C |
実際にAPI(node.js)でfield.delim等の指定をしテーブルも作成してみたのですが、入力値と実際の値は一致した形で登録されていました。
リクエストパラメータを一部抜粋
StorageDescriptor: {
Columns: [],
Compressed: false,
InputFormat: 'org.apache.hadoop.mapred.TextInputFormat',
Location: 's3://hogehoge',
NumberOfBuckets: -1,
OutputFormat: 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat',
SerdeInfo: {
SerializationLibrary: 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe',
Parameters: {
'field.delim': String.fromCharCode(1), // ^A
'collection.delim': String.fromCharCode(2), // ^B
'mapkey.delim': String.fromCharCode(3), // ^C
'serialization.format': String.fromCharCode(1), // ^A
"skip.header.line.count": 1
}
},
SortColumns: [],
StoredAsSubDirectories: false
},
これらも結果からコンソールでの動作がおかしいのではないかと思いつつも、確証がなかったためAWSサポートセンターに問い合わせてみました。
問い合わせた結果
AWSサポートセンターに問い合わせを行い、この挙動は仕様なのか確認をおこなった結果以下のような返答をいただきました。
Q.コンソールの挙動は仕様なのか?
A.意図とは異なるパラメータが設定される事象については仕様でなない
これらの値はドロップダウンリストより変更いただくことが可能ですが、デフォルトの値であっても必ず明示的に値を選択いただくことで、期待された値が選択されます。
例として、’^A’, ‘^B’, ‘^C’ を選択する場合を考えます。
この場合、 Field terminator を (\t) から ‘^A’ を変更します。
Collection terminator においても一度別の値を選択した後、再度デフォルトの値であった ‘\B’ を選択します。
Map key terminator も同様の操作を行います。
それにより、terminator は順に ‘^A’, ‘^B’, ‘^C’ となります。
こちらの挙動は直感と反する挙動であるため、現在担当部署と連携して対応を協議しております。
お客様には改善の有無やその時期などは公開しておりませんこと、予めご了承いただけますと幸いでございます。
サポートセンターの回答はデフォルトだと画面上はパラメータが表示されているが、値は予期せぬ値(多分undifined)が入っているようです。
解決策
コンソール上からテーブル作成でカスタム区切り記号のテキストファイルを指定する場合は2パターンの解決策が考えられます。
- ドロップダウンリストの値がデフォルトの値であっても必ず明示的に値を選択を行う(一度別の値を選択したあと、再度デフォルトの値を選択する)。
- SQLが作成された後に直接 CREATE TABLE文を自信で更新することで、SerDe パラメータ値を任意の値に変更する。
serialization.formatの値について
serialization.formatについてもコンソールからの設定値との関係性がいまいち分からなかったため調べました。
Athenaのコンソールから作成されるCREATE TABLE文ではserialization.formatにはField terminatorと同じものが使用されます。
Athena のコンソールにてテーブルを作成される際に Data Format にカスタム区切り記号のテキストファイル(Text File with Custom Delimiters)を選択された場合、SerDeライブラリにLazySimpleSerDeが使用されています。
LazySimpleSerdeにおいてserialization.formatは、同じくSERDEのプロパティであるfield.delimとあわせて評価されfield.delimが指定されている場合はその値が採用されfield.delimが指定されない場合は、serialization.formatの値が採用される実装になっているっぽいです。
この実装についてはこのコードが参考になりました。
LazySerDeParameters.java
https://github.com/apache/hive/blob/master/serde/src/java/org/apache/hadoop/hive/serde2/lazy/LazySerDeParameters.java
まとめ
- ドロップダウンリストの値がデフォルトの値であっても必ず明示的に値を選択を行う。
- SQLが作成された後に直接 CREATE TABLE文を自信で更新することで、SerDe パラメータ値を任意の値に変更する。
- serialization.formatの値はfield.delimの値が指定されていない場合に採用される。
おわりに
CREATE TABLE文を実行する際はコンソール上では表示されないパラメータもあるため個人的にはコンソールを信用せずに自身でSQLを更新したほうがよさそうです。
最後まで読んでいただき、ありがとうございました。今回の内容が少しでもお役に立てれば幸いです。