こんにちは。まーやです。
先日Microsoft社のイベントde:code 2019内のセッション(Understanding Query Plans and Spark UIs)で、「Koalasというものがあるよ!」と教えていただきました。とても気になるライブラリだったのでとりあえず触ってみることにしました・・・のブログです。
Koalas とは
Koalasとは、Databricks社が開発中のPython分散処理用DataFrameのライブラリです。Github上で開発されています。
https://koalas.readthedocs.io/en/latest/
もともとPySpark DataFrameというSpark用のDataFrameが存在していますが、このPySpark DataFrameはPandasとは少々書き方が異なります。 似ているところも多いけれどもともとの思想がSQL思考(Spark DataFrame)と表計算思考(Pandas)と異なるため、記法に統一感はありません。
そのため、例えば、
「分析チームがpandasを使った分析コードを送ってきたけれど、本番運用ではシングルコア処理はしんどい、Spark使って分散処理したいんや!」
となった場合、エンジニアリングチームでpandasコードをPySpark DataFrame のコードに書き換えたりする手間がありました。
そこで、書き換えの手間を最小限に抑え、なおかつお手軽分散処理しよう、と開発が始まったのがDatabricks社が開発中のKoalasです。
パンダにコアラ。動物園感がすごい。
Koalasはまだバージョン0系の開発途中ライブラリです。2019年6月12日時点でpandasの機能の約40%の開発が完了しているとのこと。正式リリースが楽しみすぎるので、とりあえずちょっぴりだけ触っていきたいと思います。
今回の環境
今回はSpark環境一発構築★なAzure Databricksを使用していきたいと思います。Azureのポータルからポチポチするだけで簡単にSpark環境が手に入ります。
https://azure.microsoft.com/ja-jp/services/databricks/
Azure Databricksは
- 1st パーティ製品扱い
- Azure AD と最初から連携済み(AWSだとただのイメージなので権限管理がちょっと面倒)
という特徴があり、チームや企業で使う場合により使いやすい感じで展開されていて便利です。
料金体系も(比較的)わかりやすいです。
https://azure.microsoft.com/ja-jp/pricing/details/databricks/
さっそくつかってみよう
https://pypi.org/project/koalas/
まずはライブラリをインストールします。PyPI に上がってるのでpipでしゅっと入ります。 このブログを書いてる最中(2019/06/10~2019/06/13)にバージョンが0.7.0から0.8.0に上がってて「うわぁぁん!(´;ω;`)」ってなったのは内緒だよ!
dbutils.library.installPyPI("Koalas","0.8.0")
dbutils.library.restartPython()
次にデータを読み込みます。もうすでにこのあたりからkoalasの本領が発揮されます。
# 今回お試しで使用するデータセットの読み込み。みんな大好きirisデータ。
from sklearn import datasets
iris = datasets.load_iris()
# 🐼での書き方
import pandas as pd
pd_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 🐨での書き方
import databricks.koalas as kl
kl_df = kl.DataFrame(iris.data, columns=iris.feature_names)
pandasとkoalasは同じ構文でかけることを目的としているので、ソースコードはほぼ(というか全部)同じです。
# 🐼
pd_df.head()
pd_df.add_prefix('panda_')
pd_df.sort_values('sepal length (cm)', ascending=False)
# 🐨
kl_df.head()
kl_df.add_prefix('koala_')
kl_df.sort_values('sepal length (cm)', ascending=False)
開発済みのAPIは↓から見ることができます。 APIリファレンスサイトまでpandasとおなじデザインです。 各APIのサンプルコードも同じです。
https://koalas.readthedocs.io/en/latest/reference/index.html
参考までにpandasのAPIリファレンスサイトはこちら。
https://pandas.pydata.org/pandas-docs/stable/reference/index.html
今までSpark DataFrameに書き直す場合、頻発する割に結構書き方を変える必要がある処理の一つに pandas.Series などがありました。ぴったり変換できる思想のAPIが存在せず、Seriesの代わりにRowで頑張ったりごにょごにょしたりする必要がありました。
koalasはpandas同様Seriesが存在するので、Seriesがらみのお悩みも解決されます。(ソースコードは適当です。多分こんな使い方することもないしこんな使い方で悩むこともないです)。
# 🐨
prices = [350, 400, 500]
tdl_snacks = kl.Series(prices, index = ['churos', 'popcorn', 'porkRiceRoll'])
tdl_snacks.loc[['churos', 'popcorn']]
ちなみに・・・
↑で書いていたコードをPyspark DataFrameで書こうとするとこんな書き方ができます。(もっといい感じにかけるかもしれません。。。)
# 🐍⚡
import pandas as pd
from pyspark.sql import SQLContext
pd_df = pd.DataFrame(iris.data, columns=iris.feature_names)
sp_df = sqlContext.createDataFrame(pd_df)
sp_rename.show()
sp_df.toDF('sp_sepal length (cm)', 'sp_sepal width (cm)', 'sp_petal length (cm)', 'sp_petal width (cm)')
sp_df.sort('sepal length (cm)', ascending=False).collect()
今回書いて遊んだコード
databricks上で実際に実行していたコードをipynbにエクスポートしました。ご興味あればどうぞ。
https://github.com/mahya8585/toolbox/blob/master/py/dataBricks/koalas.ipynb
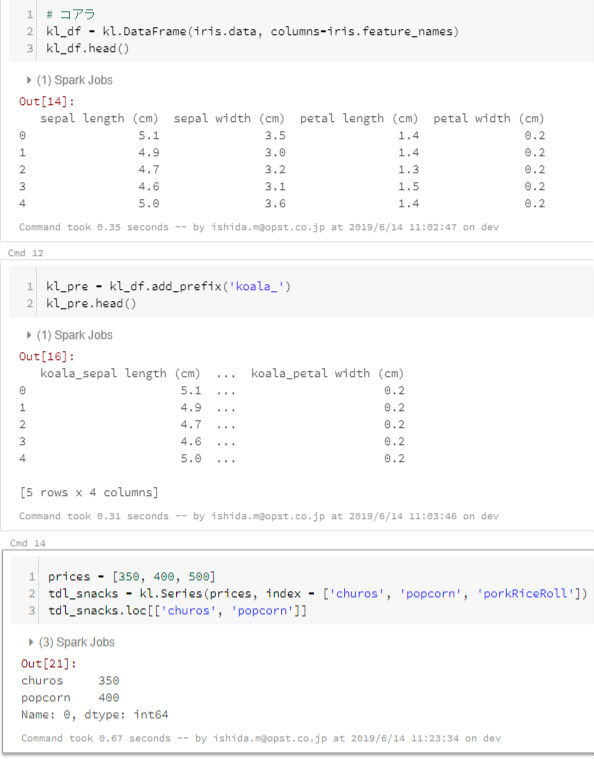
Github上の表示だとkoalas/Pyspark datagrame の実行結果表示が見づらい感じですが、databricks上でみるとそれなりに見やすい感じで表示されます。
Github上の表示↓
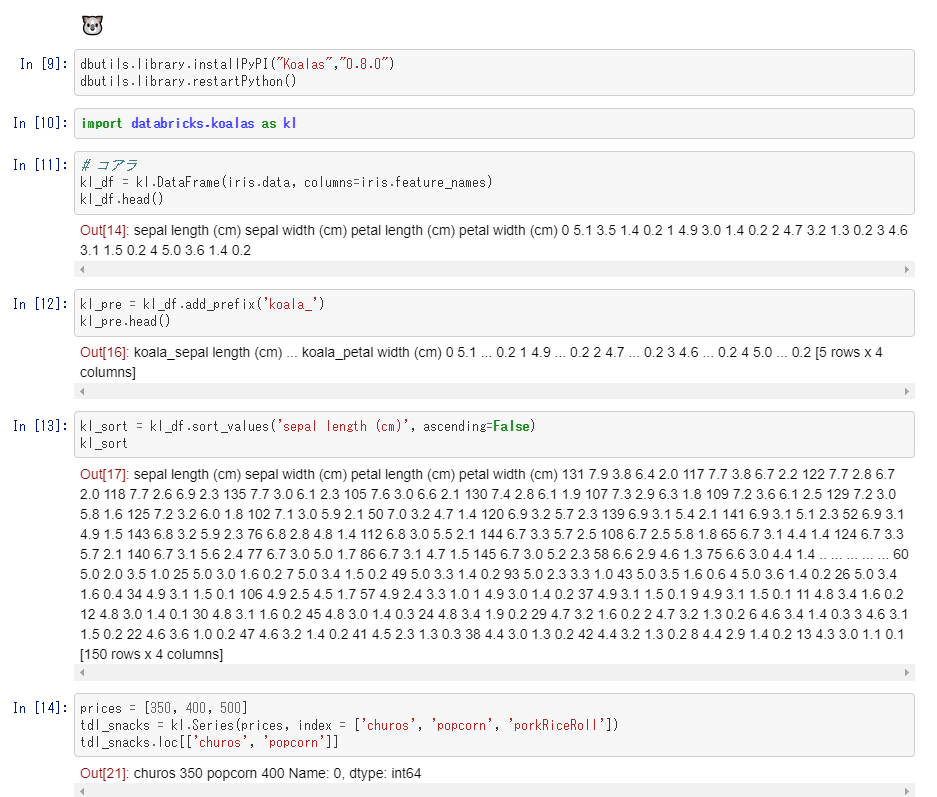
Databricks 上のnotebookの表示↓
何がうれしいのか
分散処理用のコードへの書き換えが楽・利用の敷居がひくい というのはとてもうれしいこと。すごく大雑把に書き換えるのであれば、
import pandas as pd
を
import databricks.koalas as pd
に書き換えるだけでSpark上で分散処理してくれるコードに早変わりします。(koalas as pd はとても違和感があるのでそこは直してほしいですが)。これはとても魅力的です。
分析チームの方も最初のimport文だけ変更すれば、あとは自分たちの知っている文法で処理を書けるので、変数いじったりモデリングしたりしている最中からSparkを利用できるようになり、一回の実験にかかる時間を短縮して検証することができます。
気を付けること
これは分散処理システムの特性なのでライブラリとして気を付けるというよりは使い方を意識しておく、というものですが、 処理される順番がかならず同じになるとはかぎらない という制約があります。
並列処理してまた一つにまとめるという作業が内部で行われているからですね。
順番の担保が必要な場合はkoalas処理の前の段階で担保させる必要があります。具体的にはpipelineとかflowとかの見直しをして処理を分割したり、pandasとの併用を考えたり、ということになるのかなーと。この辺りはもう少し考えていろいろな方法を頭にいれておく必要があるなと思いました。
まとめ
便利そうなので完成が待ち遠しいですね!
Github上で開発しているようなので、時間がとれたら私も貢献できたらいいなぁ・・・などと思いました。
https://github.com/databricks/koalas
来年のPyConJPとかでこのあたりの発表ができるといいな。